
코딩세상
[딥러닝 기초] 2장 딥러닝 학습의 문제점 - 학습 속도 문제와 최적화 알고리즘 본문
- 학습 속도 문제의 발생 원인
앞서 설명한 4가지의 문제중 우선 학습 속도 문제의 발생 원인에 대해 알아보겠습니다.

앞서 텐서플로우로 딥러닝 모델 구현하기 내용에서 하이퍼 파라미터 중 batch에 대해 설명했었습니다. 다시 한번 설명하면 Batch는 나눠진 데이터셋 (보통 mini-batch라고 표현)를 의미합니다.
최근엔 이렇게 Batch size를 지정하여 데이터 셋을 나눠서 학습을 진행하지만 과거에는 데이터가 증가하는데도 불구하고 전체 학습 데이터 셋을 사용하여 손실함수를 계산하기 때문에 계산량이 너무 많아지는 문제가 생겼습니다.
- 학습 속도 문제 해결 방법
이러한 문제를 해결하기 위해 전체 데이터가 아닌 부분 데이터만 활용하여 손실함수를 계산하자 라는 의견이 나왔고 이를 해결할 수 있는 손실 함수인 SDG(Stochastic Gradient Descent) 이론이 제시되었습니다.
- SGD(Stochastic Gradient Descent)
그럼 SGD(Stochastic Gradient Descent)란 무엇일까요?

위 그림을 통해 확인해보면 앞선 그림처럼 전체 데이터를 계산하는 것이 아닌 전체 데이터(batch) 대신 일부 조그마한 데이터 모음인 미니 배치(mini-batch)에 대해서만 손실함수를 계산합니다.
- GD vs SGD
그렇다면 위에서 설명한 GD와 SGD의 차이점에 대해 그림을 통해 알아보겠습니다.

- 빠른 시간에 더 많이 학습하는 SGD 알고리즘

SGD(Stochastic Gradient Descent)는 다소 부정확할 수 있지만, 훨씬 계산 속도가 빠르기 때문에 같은 시간에 더 많은 step을 갈 수 있습니다.
- SGD의 한계 : Gradient 방향성 문제

위 사진을 통해 알 수 있듯이 SGD는 gradient 값을 계산할 때 mini-batch에 따라 gradient방향의 변화가 큽니다. 즉 ,순간순간 기울기에 따라 방향을 결정하고 탐색을 하기 때문에 굉장히 비효율적으로 최솟점을 찾아가는 것을 볼 수 있습니다.
- SGD의 한계 : Learning Rate 설정 문제
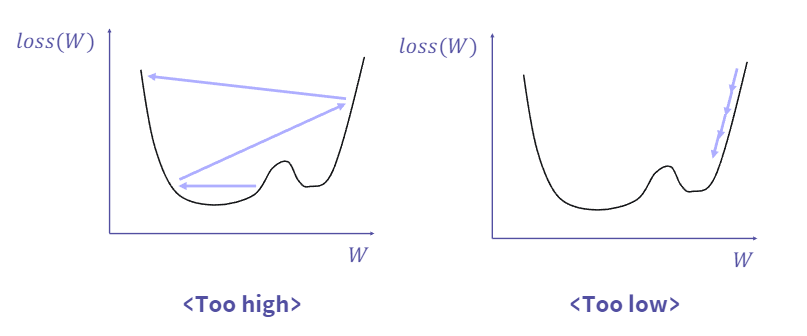
위 그래프를 통해 학습률(Learning Rate) 값에 따라 어떠한 문제점이 나타나는지 확인해볼 수 있습니다.
각 그래프에 대해 설명하기 전에
학습률(Learning Rate)란? 하이퍼 파라미터의 하나로써 모델이 학습을 진행할 때어느 정도의 크기로 기울기가 줄어드는 지점으로 이동하겠는가를 나타내는 지표입니다.
SGD는 간단히 말하면 그래프의 최솟값을 찾아가기 위한 방법이라고 생각하면 편합니다. 그렇다면 이 최솟값을 찾아가기 위한 과정에서 왼쪽 그래프처럼 학습률이 과도하게 높아지게 되면 최솟값을 찾지 못하게 될것입니다.
그렇다면 반대로 학습률이 과도하게 작으면 어떤 문제점이 생길까요? 바로 학습에 엄청난 시간이 걸리게 된다는 문제입니다. 그래서 우리는 이 학습률(Leraning Rate)를 적절하게 설정하여 가장 빠르게 최적의 값을 도출해낼 수 있어야합니다.
- 다양한 최적화 알고리즘의 등장
하지만 SGD 역시 장점 뿐만 아니라 위에서 설명 했듯이 단점도 가지고 있었기 때문에 이를 해결한 여러가지 최적화 알고리즘이 등장하기 시작하였습니다.
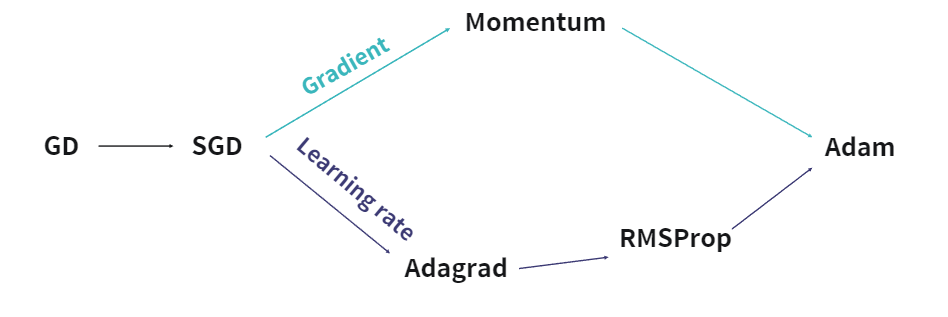
- Momentum
그럼 먼저 Momemtum에 대해 알아보겠습니다.
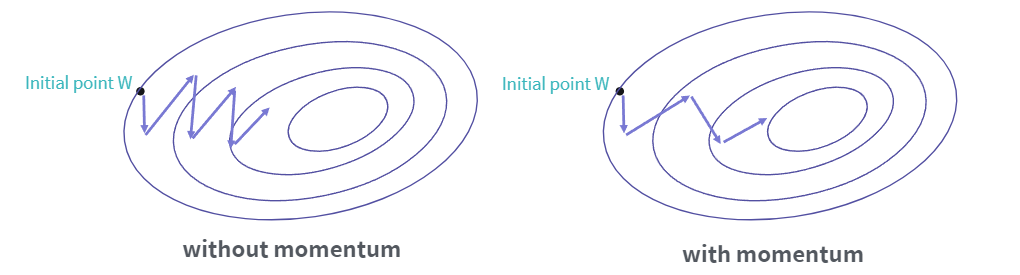
Momentum은 위 그림에서 확인할 수 있듯이 Gradient(기울기)를 개선하여 발전한 최적화 알고리즘 입니다.
Momentum은 과거에 이동했던 방식을 기억하면서 그 방향으로 일정 정도를 추가적으로 이동하는 방식을 사용하며, Momentum을 사용한것과 사용하지 않은것을 비교했을 때 사용한 쪽이 더 적은 횟수로 더 많이 학습을 진행한 것을 확인할 수 있습니다.
- AdaGrad(Adaptive Gradient)
AdaGrad(Adaptive Gradient)는 Gradient(기울기)를 개선시켜서 나온 최적화 알고리즘입니다.
AdaGrad(Adaptive Gradient)는 학습을 진행하면서 많이 변화하지 않은 변수들의 Learning Rate를 크게하고, 많이 변화했던 변수들의 Learning Rate를 작게하여 학습을 진행합니다.
하지만 이것의 문제점은 과거의 기울기를 제곱해서 계속 더하기 때문에 학습이 진행될수록 갱신 강도가 약해진다는 단점이 있습니다.
- RMSProp
AdaGrad(Adaptive Gradient)가 가지고 있는 무한히 학습하다보면 순간 갱신량이 0에 가까워 학습이 되지 않는 문제를 개선해서 나온 최적화 알고리즘이 RMSProp입니다.
이 최적화 알고리즘은 과거의 기울기는 잊고 새로운 기울기 정보를 크게 반영하여 학습을 진행합니다.
- Adam
이 최적화 알고리즘은 최근에 가장 많이 사용하는 최적화 알고리즘으로써 위에서 설명한 Momentum과 RMSProp를 합친 가장 발전된 최적화 알고리즘 입니다.
- 다양한 최적화 알고리즘 요약
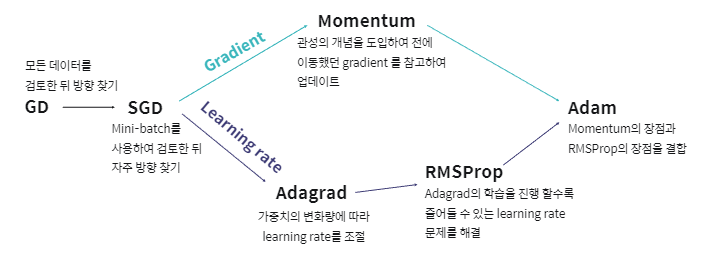
따라서 위 그림을 통해 지금까지 설명한 최적화 알고리즘을 요약하여 확인할 수 있습니다.
# 출처
엘리스 AI 트랙 7기 - [강의자료] 딥러닝 학습의 문제점
'인공지능' 카테고리의 다른 글
| [딥러닝 기초] 2장 딥러닝 학습의 문제점 - 초기값 설정 문제와 방지 기법 (0) | 2023.09.07 |
|---|---|
| [딥러닝 기초] 2장 딥러닝 학습의 문제점 - 기울기 소실 문제와 방지 기법 (0) | 2023.09.07 |
| [딥러닝 기초] 2장 딥러닝 학습의 문제점 - 딥러닝 모델 학습의 문제점 (0) | 2023.09.06 |
| [딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 텐서플로우로 딥러닝 모델 구현하기 (0) | 2023.09.04 |
| [딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 텐서플로우 기초 사용법 (0) | 2023.09.03 |



