
코딩세상
[딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 텐서플로우로 딥러닝 모델 구현하기 본문
- 딥러닝 모델 구현 순서
딥러닝 모델은 아래와 같은 순서로 진행되게 됩니다.
- 데이터셋 준비하기
- 딥러닝 모델 구축하기
- 모델 학습시키기
- 평가 예측하기
오늘은 딥러닝 모델을 구현하는 4단계를 알아보겠습니다.
- 1. 데이터셋 준비하기 : Epoch와 Batch
데이터셋을 준비하는 과정은 여러가지 과정을 통해 준비할 수 있습니다. AI 허브, 공공데이터포털과 같은 데이터셋 사이트를 이용하여 원하는 데이터셋 탐색, kaggle 서칭을 통한 데이터셋 탐색, 직접 필요한 데이터 셋 제작 등 많은 방법을 확인 할 수 있습니다.
이렇게 데이터셋을 준비하면 학습 시키기 전에 우리는 이러한 데이터셋을 얼마나 분리하여 인공지능 모델에 학습시킬지 정할 수 있습니다.
데이터의 양, 복잡도에 따라 우리가 설정하는 하이퍼 파라미터의 값은 달라질 것입니다.
그럼 데이터셋 준비하기 단계에서 우리가 설정할 수 있는 하이퍼 파라미터는 어떤것이 있을까요?
소제목에 적혀있듯이 대표적으로 Epoch와 Batch를 예로 들 수 있습니다.
여기서 Epoch와 Batch란?
Epoch : 한 번의 epoch는 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
Batch : 나눠진 데이터셋 (보통 mini-batch라고 표현)
[iteration은 epoch를 나누어서 실행하는 횟수를 의미]
- Epoch와 Batch 예시

예를 들어 총 데이터가 1000개이고, Batch size를 100이라고 설정하였을 때
- 1 iteration = 100개의 데이터에 대해서 학습을 진행
- 1 epoch = 1000/Batch size = 10 iteration
라고 설명할 수 있습니다.
- 데이터셋 준비하기 코드 예시
위에서 설명한 내용을 토대로 데이터셋을 준비하는 코드를 작성해보겠습니다.
data = np.random.sample((100, 2))
labels = np.random.sample((100, 1))
# numpy array로부터 데이터셋 생성
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
np. random.sample()함수의 경우 사용자가 설정한 행렬의 크기에 맞춰 numpy 배열을 생성합니다.
따라서 위 코드에서는 data에는 (100, 2)의 numpy 행렬이, labels에는 (100, 1)의 numpy 행렬이 생성되게 됩니다.
tf.data.Dataset.from_tensor_slices() 함수의 경우 입력한 데이터에 맞춰 쪼깨주는 역할을 합니다.
이렇게 구성된 dataset에 dataset.batch(32)를 설정하게 되면 batch size가 32의 크기를 가질 수 있게 dataset을 나눠주게 됩니다.
- 2. 딥러닝 모델 구축하기 : 고수준 API 활용

이렇게 앞에서 설명한 과정을 통해 데이터셋을 구축하였다면 다음으로는 데이터셋에 적합한 딥러닝 모델을 구축해야됩니다.
이를 위한 고수준 API로 Keras를 예로 들 수 있는데 Keras는 텐서플로우의 패키지로 제공되는 고수준 API로서 딥러닝 모델을 간단하고 빠르게 구현할 수 있습니다.
- 딥러닝 모델 구축을 위한 Keras 메소드(1)
그렇다면 Keras를 사용하여 딥러닝 모델을 어떻게 구축할 수 있을까요?
앞선 설명에서 우리는 딥러닝 모델이 아래와 같은 사진처럼 구성되어 있다는 것을 학습하였습니다.
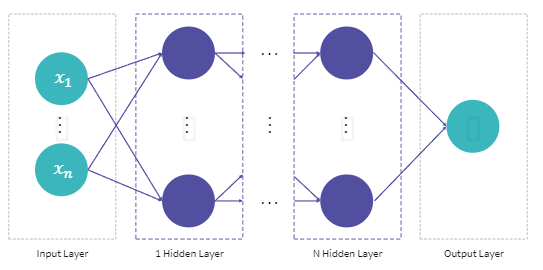
즉, 위의 사진처럼 입력층, 은닉층, 출력층을 Keras를 사용하여 직접 구성하는 것입니다.
우선 모델을 만들기 전 모델 클래스 객체를 생성해줘야합니다.
tf. keras.models.Sequential() 함수를 사용하여 딥러닝 모델의 객체를 생성해줍니다.
다음으로 모델의 각 Layer를 구성 해줘야합니다. Layer 구성은 tf.keras.layers.Dense(units, activation) 함수를 사용하여 구성합니다.
여기서 unit과 activation은 아래와 같은 의미를 지니게 됩니다.
- units : 레이어 안의 Node의 수
- activation : 적용 할 activation 함수 설정
- Input Layer의 입력 형태 지정하기

첫 번째 즉, Input Layer는 입력 형태에 대한 정보를 필요로 합니다. input_shape / input_dim 인자를 설정하여 데이터의 입력 크기를 지정해주게 됩니다.
- 모델 구축하기 코드 예시(1)
그럼 위에서 설명한 내용들을 가지고 간단한 딥러닝 모델을 구축해볼까요?
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_dim=2, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
이처럼 딥러닝 모델의 뼈대를 만드는 tf.keras.models.Sequential()함수와 tf.keras.layers.Dense()함수를 사용하여 간단하게 딥러닝 모델을 구축하였습니다.
- 딥러닝 모델 구축을 위한 Keras 메소드(2)
앞서 설명한 내용은 tf.keras.models.Sequential() 함수 내에 배열의 형태로 Dense Layer 넣었지만 [model].add() 함수를 사용하면 배열의 형태로 넣지 않아도 모델에 Layer를 추가할 수 있습니다.
사용하는 방법은 [model].add(tf.keras.layers.Dense(units, activation))과 같이 작성하여 사용할 수 있습니다.
- units : 레이어 안의 Node의 수
- activation : 적용 할 activation 함수 설정
그러면 설명한 방법을 토대로 간단한 모델 구성 코드를 작성하면 아래와 같이 작성할 수 있습니다.
model = tf.kears.models.Sequential()
model.add(tf.keras.layers.Dense(10, input_dim = 2, activation='sigmoid'))
model.add(tf.keras.layers.Dense(10, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
- 3. 딥러닝 모델 학습시키기 : Keras 메소드
딥러닝 모델을 학습시키기 위해서는 .compile()과 .fit() 두개의 함수를 사용하게 됩니다.
아래의 표를 통해 각 함수가 어떤 역할을 하는지 확인할 수 있습니다.
| 모델 학습 방식을 설정하기 위한 함수 [model].compile(optimizer, loss) - optimizer : 모델 학습 최적화 방법 - loss : 손실 함수 설정 |
모델을 학습시키기 위한 함수 [model].fit(x, y) - x : 학습 데이터 - y : 학습 데이터의 label |
- 딥러닝 모델 학습시키기 코드 예시
그렇다면 두 함수를 예제 코드를 통해 어떻게 사용하는지 알아보겠습니다.
model.compile(loss='mean_squared_error', optimizer='SGD')
model.fit(dataset, epochs = 100)
이처럼 .compile() 함수에서는 우리가 사용하고자 하는 손실 함수와 optimizer를 설정하여 모델 학습 방식을 지정해주고, .fit()함수에 사용하고자 하는 데이터셋과 앞에서 배운 학습 횟수인 epochs를 설정해주어 모델의 학습을 진행할 수 있습니다.
- 4. 평가 및 예측하기 : Keras 메소드
이렇게 데이터셋을 만들고 모델을 구축하고 구축한 모델을 데이터셋을 통해 학습을 시켰다면 우리는 이 모델이 제대로 학습했는지 평가를 진행해야합니다.
평가를 위한 Keras의 메소드는 기본적으로 .evaluate()를 사용하며, 예측은 .predict()함수를 사용할 수 있습니다.
| 모델을 평가하기 위한 메소드 [model].evaluate(x, y) - x : 테스트 데이터 - y : 테스트 데이터의 label |
모델로 예측을 수행하기 위한 함수 [model].predict(x) - x : 예측하고자 하는 데이터 |
.
- 평가 및 예측하기 코드 예시
그렇다면 위 함수들을 어떻게 사용해야하는지 아래의 코드를 통해 알아보겠습니다.
# 테스트 데이터 준비하기
dataset_test = tf.data.Dataset.from_tensor_slices((data_set, labels_test))
dataset_test = dataset.batch(32)
# 모델 평가 및 예측하기
model.evaluate(dataset_test)
predicted_labels_test = model.predict(data_set)
첫 번째 단계인 데이터셋 준비하기에서는 훈련하기 위한 데이터를 준비했다면 훈련이 다 끝나고 나서 테스트를 하기 위한 데이터셋을 만들어주어야 합니다. 그리고 이 데이터 셋을 가지고 학습한 모델에 넣어 과연 모델이 얼마나 높은 정확도를 가지고 있는지 .evaluate()를 사용하여 평가할 수 있고, 우리가 원하는 결과를 도출하는지 .predict()를 통해 확인할 수 있습니다.
여기서 의문이라면 앞에서 설명한 데이터셋과 여기서 준비한 데이터셋은 서로 같은게 아닌가 하는 의문이 들 수 있습니다. 예를들어 유명한 데이터셋인 mnist를 사용할 때 데이터셋 준비하기 단계에서 훈련 데이터와 테스트 데이터를 나누지만 이 내용은 나중에 좀 더 자세히 다뤄보겠습니다.
# 출처
엘리스 AI 트랙 7기 - [강의자료] 텐서플로우와 딥러닝 학습 방법
'인공지능' 카테고리의 다른 글
| [딥러닝 기초] 2장 딥러닝 학습의 문제점 - 학습 속도 문제와 최적화 알고리즘 (0) | 2023.09.06 |
|---|---|
| [딥러닝 기초] 2장 딥러닝 학습의 문제점 - 딥러닝 모델 학습의 문제점 (0) | 2023.09.06 |
| [딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 텐서플로우 기초 사용법 (0) | 2023.09.03 |
| [딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 텐서플로우(TensorFlow) (0) | 2023.08.31 |
| [딥러닝 기초] 2장 텐서플로우와 딥러닝 학습 방법 - 딥러닝 모델의 학습 방법 (0) | 2023.08.30 |



